前言
之前的一篇文章介绍了索引来提高数据库的查询性能,这其实仅仅是个开始。也许假设缺乏适当的保养,索引你以前建立的,甚至成为拖累,成为帮凶下降数据库的性能。
寻找碎片
消除碎片索引维护可能是最常规的任务,,议是当碎片等级为 5% - 30% 之间时採用 REORGANIZE 来“重整”索引。假设达到 30% 以上则使用 REBUILD 来“重建”索引。决定採用何种手段和操作时机可能需要考虑很多的因素,下面4条是你必需要考虑的:
- 备份的计划
- server的负载
- 磁盘剩余空间
- 回复(Recovery) 模型
PS:尽管碎片与性能紧密相关,但某些特定情况下他能够被忽略。比方你有一张带有聚集索引的表,差点儿全部针对该表的处理不过依据主键取出一条数据。该场合下碎片的影响能够忽略不计。
那么如何确定某个索引的碎片状况呢?使用系统函数sys.dm_db_index_physical_stats 及系统文件夹 sys.Indexes。演示样例脚本例如以下:
-- 获取指定表(演示样例:ordDemo)上全部索引的信息SELECT sysin.name as IndexName ,sysIn.index_id ,func.avg_fragmentation_in_percent ,func.index_type_desc as IndexType ,func.page_countFROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID(N'ordDemo'), NULL, NULL, NULL) AS funcJOIN sys.indexes AS sysInON func.object_id = sysIn.object_id AND func.index_id = sysIn.index_id-- 聚集索引的 Index_id 为 1-- 非聚集索引为 Index_id>1-- 下面脚本用 WHERE 子句进行了筛选(剔除了没有索引的表)-- 该脚本返回数据库全部的索引,可能花费较长时间!
SELECT sysin.name as IndexName ,sysIn.index_id ,func.avg_fragmentation_in_percent ,func.index_type_desc as IndexType ,func.page_count FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS func JOIN sys.indexes AS sysIn ON func.object_id = sysIn.object_id AND func.index_id = sysIn.index_id WHERE sysIn.index_id>0;
输出截图例如以下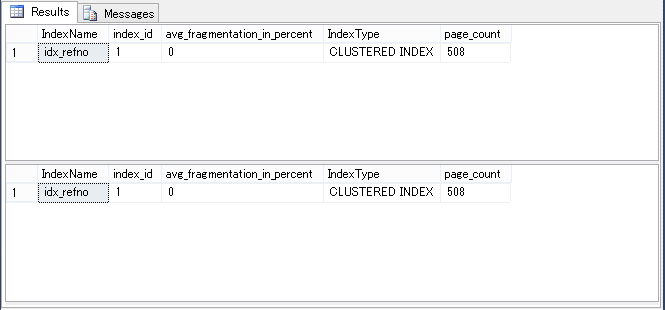
演示样例数据库的碎片为0。这是由于碎片是在运行增删改时产生的,我们的数据库还没有做过类似操作。
填充因子
前面提到过数据以8KB 数据页的方式存放在数据库中,如果你有一张建立了聚集索引的表。每当有数据插入时。数据库会依据主键找到插入位置(数据页)并写入信息。
如果该数据页已经满了或者不够空间存放新的数据,数据库会建立一个新的8KB 数据页,而这个新建的过程会造成I/O消耗。
填充因子用来降低这样的情况的发生,假设你设定填充因子为10,那么你的数据初始仅使用8KB 数据页中的10%,当插入新纪录时基本不用操心会发生多余的I/O消耗,由于数据页中预留了90%的空间。
填充因子也是把双刃剑。他在添加写操作性能的同一时候,减少了读操作的性能。
【填充因子仅当建立索引或重建(rebuildi)索引时起作用。对于一般的DML操作无效(数据页总是填充到100%)】
下面脚本帮助你了解索引的填充因子值:
SELECT OBJECT_NAME(OBJECT_ID) AS TableName ,Name as IndexName ,Type_Desc ,Fill_FactorFROM sys.indexesWHERE -- 这里通过WHERE筛选来只表示聚集索引和非聚集索引 type_desc<>'HEAP'你还能够查看数据server上默认的填充因子值:
SELECT Description ,Value_in_useFROM sys.configurationsWHERE Name ='fill factor (%)'PS:0表示不保留不论什么预留空间。 通过下面脚本来设置填充因子的值:
ALTER INDEX [idx_refno] ON [ordDemo]REBUILD WITH (FILLFACTOR= 80)GO-- 假设要设定server上的默认值。使用下面脚本Sp_configure 'show advanced options', 1GORECONFIGUREGOsp_configure 'fill factor', 90GORECONFIGUREGO在一张静态表(偶然更新)的表上建议採用较大的填充因子(90%以上)。在读写频繁的表上建议採用较低的填充因子(70% - 80%)。
特别的。当你的聚集索引建立在一个自增字段上时,设定填充因子为100%也没有问题。由于新插入的数据总是在全部数据的最后,不会发生插入记录与记录之间的情况。
重建(REBUILD)索引来提高索引效率
重建索引的作用顾名思义,他带来的优点包含消除碎片,统计值(statistics)更新,数据页中物理排序顺序的对齐。另外他还会依据填充因子来压缩数据页,(假设必要的话)新增数据页。优点一箩筐,仅仅是这个操作很耗资源。会花费相当长的时间。假设你决定開始重建索引,你还须要知道他有两种工作模式:
离线模式:这是默认的重建索引模式,它将锁定表直到重建完毕。假设表非常大。会导致用户(好几个小时都)无法使用该表。相比在线模式来说离线模式工作更快,消耗的TempDb的空间更小。
在线模式:假设客观条件不同意你锁定表,你就仅仅能选择在线模式,这将耗费很多其它的时间和server资源。值得一提的是假设你的表包括了varchar (max), nvarchar (max), text 类型字段的话,将无法在该模式下进行重建索引。
【提示:该模式选择仅在开发版/企业版中支持。其它版本号默认使用离线模式。】
下面是重建索引的演示样例脚本:
-- 在线模式下重建索引 idx_refnoALTER INDEX [idx_refno] ON [ordDemo]REBUILD WITH (FILLFACTOR=80, ONLINE=ON)GO-- 离线模式下重建索引 idx_refnoALTER INDEX [idx_refno] ON [ordDemo]REBUILD WITH (FILLFACTOR=80, ONLINE=OFF)GO-- 重建 ordDemo 表上的全部索引ALTER INDEX ALL ON [ordDemo]REBUILD WITH (FILLFACTOR=80, ONLINE=OFF)GO-- 重建索引 idx_reno (DROP_EXISTING=ON)CREATE CLUSTERED INDEX [idx_refno] ON [ordDemo](refno)WITH(DROP_EXISTING = ON,FILLFACTOR = 70,ONLINE = ON)GO-- 使用 DBCC DBREINDEX 重建 ordDemo 表上的全部索引DBCC DBREINDEX ('ordDemo')GO-- 使用 DBCC DBREINDEX 重建 ordDemo 表上的一个索引DBCC DBREINDEX ('ordDemo','idx_refno',90)GO 【DBCC DBREINDEX 将在兴许版本号被废弃】
基于作者的个人经验,在一张大数据量的表上进行重建操作时,使用批量日志恢复(bulk-logged recovery)或简单恢复(simple recovery)比較好,这能防止日志文件过大。只是须要提醒你的是,切换恢复模式时会打断数据库的备份链。所以假设你之前是全然恢复模式(full recovery),记得重建后再切换回来。
重建时一定要有耐心。长的可能花上1天,冒昧地打断他是很危急的(数据库可能进入恢复模式)。
运行该操作的用户必须是该表的全部者,或是该server的sysadmin一员,或是该数据库的db_owner / db_ddladmin。
重整(REORGANIZE)索引来提高索引效率
重整不会锁定不论什么对象。他是一个优化当前 B-Tree,组织数据页的处理及碎片整理。
重整索引处理演示样例脚本例如以下:
-- 重整 "ordDemo" 表上的 "idx_refno" 索引ALTER INDEX [idx_refno] ON [ordDemo]REORGANIZEGO-- 重整 ordDemo 表上全部索引ALTER INDEX ALL ON [ordDemo]REORGANIZEGO-- 重整 AdventureWorks2012 数据库中 ordDemo 表上全部索引DBCC INDEXDEFRAG ('AdventureWorks2012','ordDemo')GO-- 重整 AdventureWorks2012 数据库中 ordDemo 表上索引 idx_refnoDBCC INDEXDEFRAG ('AdventureWorks2012','ordDemo','idx_refno')GO 注意:运行该操作的用户必须是该表的全部者,或是该server的sysadmin一员,或是该数据库的db_owner / db_ddladmin。
发现缺失的索引
如今你已经了解索引带来的性能提升,但实际情况下非常难在一開始就建立好足够正确及必要的索引,我们要如何才干推断出哪些表须要索引,哪些索引建立得不正确呢?
通常情况下,SQL Server 会利用既有的索引来执行查询脚本,假设没有找到索引他会自己主动生成一个并存放在DMV(dynamic management view)中。
每当SQL Server 服务重新启动的时候这些信息会被清除,所以在获取缺失索引的过程中最好保持SQL Server 服务的执行,直到全部的业务逻辑跑完一遍。
可參照下面链接来获取很多其它相关信息:
提供一个现成的脚本:
SELECT avg_total_user_cost * avg_user_impact * (user_seeks + user_scans) AS PossibleImprovement ,last_user_seek ,last_user_scan ,statement AS Object ,'CREATE INDEX [IDX_' + CONVERT(VARCHAR,GS.Group_Handle) + '_' + CONVERT(VARCHAR,D.Index_Handle) + '_' + REPLACE(REPLACE(REPLACE([statement],']',''),'[',''),'.','') + ']' +' ON ' + [statement] + ' (' + ISNULL (equality_columns,'') + CASE WHEN equality_columns IS NOT NULL AND inequality_columns IS NOT NULL THEN ',' ELSE '' END + ISNULL (inequality_columns, '') + ')' + ISNULL (' INCLUDE (' + included_columns + ')', '') AS Create_Index_SyntaxFROM sys.dm_db_missing_index_groups AS GINNER JOIN sys.dm_db_missing_index_group_stats AS GSON GS.group_handle = G.index_group_handleINNER JOIN sys.dm_db_missing_index_details AS DON G.index_handle = D.index_handleOrder By PossibleImprovement DESC PS:你获取到的信息是一个提议列表,终于的决定权在你,另外DMV最多仅仅保存500个索引。 发现未使用的索引
我们建立了索引来改进性能,但假设建立的索引没有被利用到,那反而成累赘了。与前一个小节同样的原因,保持SQL Server 服务的执行。直到全部的业务逻辑跑完一遍。执行一下脚本:
SELECT ind.Index_id, obj.Name as TableName, ind.Name as IndexName, ind.Type_Desc, indUsage.user_seeks, indUsage.user_scans, indUsage.user_lookups, indUsage.user_updates, indUsage.last_user_seek, indUsage.last_user_scan, 'drop index [' + ind.name + '] ON [' + obj.name + ']' as DropIndexCommandFROM Sys.Indexes as indJOIN Sys.Objects as objON ind.object_id=obj.Object_IDLEFT JOIN sys.dm_db_index_usage_stats indUsageON ind.object_id = indUsage.object_idAND ind.Index_id=indUsage.Index_idWHERE ind.type_desc<>'HEAP' and obj.type<>'S'AND objectproperty(obj.object_id,'isusertable') = 1AND (isnull(indUsage.user_seeks,0) = 0AND isnull(indUsage.user_scans,0) = 0AND isnull(indUsage.user_lookups,0) = 0)ORDER BY obj.name,ind.NameGO获取这些信息后。採取如何的行动由你决定。可是当你决定删除某个索引时请注意下面两点:
- 假设当前索引是个主键或唯一键。他能保证数据的完整性
- 唯一索引即使本身并没有被使用,但能给优化器提供信息,从而帮助它生成更好的运行计划
建立索引视图(indexed view)来改善性能
视图是个存储的查询,表现得像表一样。它有两个主要优点:
- 限制用户仅仅能訪问某几张表中特定字段及特定数据
- 同意开发人员通过自己定义的方式把原始信息组织成面向用户的逻辑视图
索引视图在创建时就解析/优化好查询语句,并把相关信息以物理形式存放在数据库中。再决定使用索引视图前请考虑下面建议:
- 视图不应该參照其它视图
- 试图能够參照不论什么原始表
- 字段名必须显式明白的定义好合适的别名
另外假设针对该对象的处理查询少更新多,又或者原始表是个常常更新的表,那么使用索引视图并非非常合适。
假设你有个查询包括较多的合计(aggregation)/联合(join)并且表的数据量非常大。那么能够考虑使用索引视图。使用索引视图必须设定下面參数(NUMERIC_ROUNDABORT为OFF。其余为ON)
- ARITHABORT
- CONCAT_NULL_YIELDS_NULL
- QUOTED_IDENTIFIER
- ANSI_WARNINGS
- ANSI_NULLS
- ANSI_PADDING
- NUMERIC_ROUNDABORT
演示样例脚本:
CREATE VIEW POViewWITH SCHEMABINDINGASSELECT POH.PurchaseOrderID ,POH.OrderDate ,EMP.LoginID ,V.Name AS VendorName ,SUM(POD.OrderQty) AS OrderQty ,SUM(POD.OrderQty*POD.UnitPrice) AS Amount ,COUNT_BIG(*) AS CountFROM [Purchasing].[PurchaseOrderHeader] AS POHJOIN [Purchasing].[PurchaseOrderDetail] AS PODON POH.PurchaseOrderID = POD.PurchaseOrderIDJOIN [HumanResources].[Employee] AS EMPON POH.EmployeeID=EMP.BusinessEntityIDJOIN [Purchasing].[Vendor] AS VON POH.VendorID=V.BusinessEntityIDGROUP BY POH.PurchaseOrderID ,POH.OrderDate ,EMP.LoginID ,V.NameGO-- 在视图上建立一个聚集索引使得它成为使得它成为索引视图CREATE UNIQUE CLUSTERED INDEX IndexPOView ON POView(PurchaseOrderID)GO你能够对照一下查询语句与查询索引视图的运行计划,索引视图的方式提供了更好的查询性能:
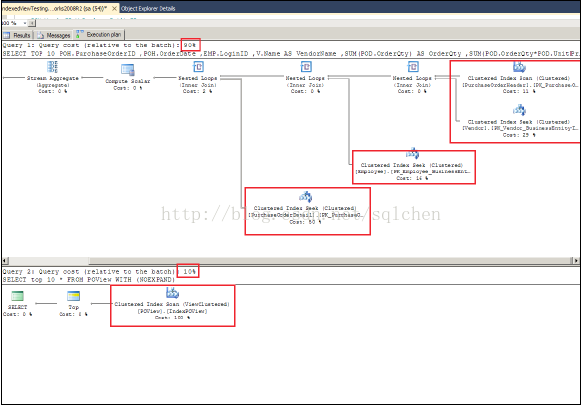
SQL Server 的查询优化器总是尝试找到最佳的运行计划,有时候尽管你建立了索引视图,但优化器依旧使用了原始表上的索引,此时你能够使用 WITH NOEXPAND 来强制使用索引视图上的索引(而不是原始表上的索引)。
索引视图在 SQL Server 2012 的各个版本号上都有支持。在开发版或企业版中查询处理器甚至能以此来把匹配索引视图的查询都优化了。
索引视图建立时必须带上 WITH SCHEMABINDING,以此保证用到的字段不会被改动掉。
假设索引视图包括了 GROUP BY 子句,则必须在 SELECT 子句中包括 COUNT_BIG (*),而且不能指定 HAVING, CUBE, 以及 ROLLUP。
使用计算字段(Computed Columns)上的索引来改善性能
首先来介绍一下计算字段(Computed Columns)。它通过一个表达式来引用同一张表的其它字段,然后运算出一个结果。
这个字段的值会在每次被调用时都又一次计算。除非你在建立时带上 PERSISTED 标记。
在决定是否在计算字段上建立索引前,须要考虑一下几点:
- 计算字段为 Image, Text, 或 ntext 的情况,它仅仅能作为非聚集索引的非keyword段(non-key column)
- 计算字段表达式不能是 REAL 或 FLOAT 类型
- 计算字段应当是精确的(?)
- 计算字段应当是确定的(输入同样的值,输出同样的结果)
- 计算字段假设使用了函数(function)。无论是用户函数还是系统函数,表及函数的拥有者必须是同一个
- 针对多行记录的函数(比方:SUM, AVG)不能在计算字段中使用
- 增删改会改变计算字段上索引的值,所以必须设定下面6个參数。
SET ANSI_NULLS ON SET ANSI_PADDING ON SET ANSI_WARNINGS ON SET ARITHABORT ON SET CONCAT_NULL_YIELDS_NULL ON SET QUOTED_IDENTIFIER ON SET NUMERIC_ROUNDABORT OFF
以下我们来看一个完整的样例:
1. 设定系统变量,并建立我们的測试数据表
SET ANSI_NULLS ONSET ANSI_PADDING ONSET ANSI_WARNINGS ONSET ARITHABORT ONSET CONCAT_NULL_YIELDS_NULL ONSET QUOTED_IDENTIFIER ONSET NUMERIC_ROUNDABORT OFFSELECT [SalesOrderID] ,[SalesOrderDetailID] ,[CarrierTrackingNumber] ,[OrderQty] ,[ProductID] ,[SpecialOfferID] ,[UnitPrice]INTO SalesOrderDetailDemoFROM [AdventureWorks2012].[Sales].[SalesOrderDetail]GO2. 建立一个用户自己定义函数。然后再建立一个计算字段并使用这个函数
CREATE FUNCTION[dbo].[UDFTotalAmount] (@TotalPrice numeric(10,3), @FreightTINYINT)RETURNS Numeric(10,3)WITH SCHEMABINDINGASBEGINDECLARE @NetPrice Numeric(10,3)SET @NetPrice = @TotalPrice + (@TotalPrice*@Freight/100)RETURN @NetPriceENDGO--adding computed column SalesOrderDetailDemo tableALTER TABLE SalesOrderDetailDemoADD [NetPrice] AS [dbo].[UDFTotalAmount] ( OrderQty*UnitPrice,5)GO3. 建立一个聚集索引。打开性能指标开关,并运行一条查询(注意此时我们还没有在计算字段上建立索引。)
CREATE Clustered Index idx_SalesOrderID_SalesOrderDetailID_SalesOrderDetailDemoON SalesOrderDetailDemo(SalesOrderID,SalesOrderDetailID)GO--checking SalesOrderDetailDemo with statistics option ON to--measure performanceSET STATISTICS IO ONSET STATISTICS TIME ONGO--checking SELECT statement without having Index on ComputedColumnSELECT * FROM SalesOrderDetailDemo WHERE NetPrice>5000GO输出的性能结果例如以下:
| SQL Server parse and compile time: CPU time = 650 ms, elapsed time = 650 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (3864 row(s) affected) Table 'SalesOrderDetailDemo'. Scan count 1, logical reads 757, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 562 ms, elapsed time = 678 ms. |
4. 在计算字段上建立索引之前,能够用下面的脚本确认是否满足之前提到的创建要求:(返回值:0不满足。1满足)
SELECTCOLUMNPROPERTY( OBJECT_ID('SalesOrderDetailDemo'),'NetPrice','IsIndexable') AS 'Indexable?',COLUMNPROPERTY( OBJECT_ID('SalesOrderDetailDemo'),'NetPrice','IsDeterministic') AS 'Deterministic? ' ,OBJECTPROPERTY(OBJECT_ID('UDFTotalAmount'),'IsDeterministic')'UDFDeterministic?' ,COLUMNPROPERTY(OBJECT_ID('SalesOrderDetailDemo'),'NetPrice','IsPrecise') AS 'Precise?
'
5. 满足要求的情况下建立索引。并再次运行先前的查询语句CREATE INDEX idx_SalesOrderDetailDemo_NetPriceON SalesOrderDetailDemo(NetPrice)GOSELECT * FROM SalesOrderDetailDemo WHERE NetPrice>5000GO这次的性能结果例如以下:
| SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (3864 row(s) affected) Table 'SalesOrderDetailDemo'. Scan count 1, logical reads 757, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 546 ms, elapsed time = 622 ms. |
SELECT CASE index_id WHEN 0 THEN 'HEAP' WHEN 1 THEN 'Clustered Index' ELSE 'Non-Clustered Index' END AS Index_Type, SUM(CASE WHEN FilledPage > PageToDeduct THEN (FilledPage-PageToDeduct) ELSE 0 END )* 8 Index_SizeFROM( SELECT partition_id, index_id, SUM (used_page_count) AS FilledPage, SUM ( CASE WHEN (index_id < 2) THEN (in_row_data_page_count + lob_used_page_count + row_overflow_used_page_count) ELSE lob_used_page_count + row_overflow_used_page_count END ) AS PageToDeduct FROM sys.dm_db_partition_stats GROUP BY partition_id,index_id) AS InnerTableGROUP BY index_idGOPS: 输出的单元KB